Method
|
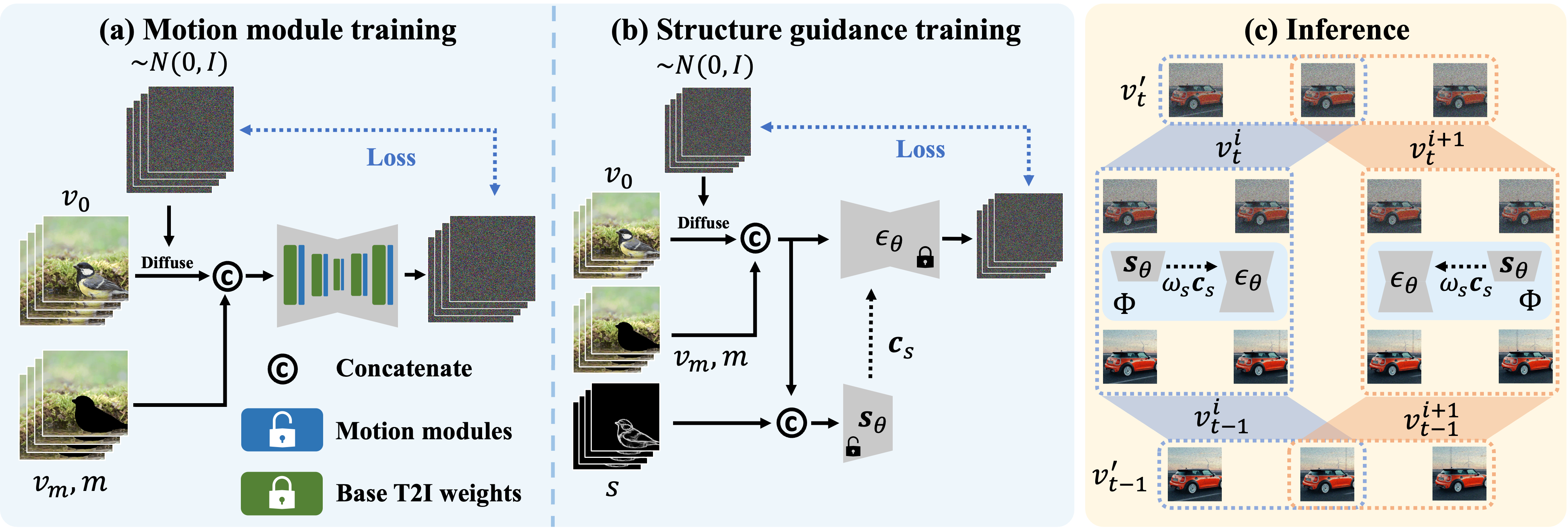
In the training phase of our methodology, we employ a two-step approach. (a) Motion modules are integrated after each layer of the primary Text-to-Image (T2I) inpainting model, optimized for the video in-painting task via synthetic masks applied to the video data. (b) During the second training step, we retain the parameters in the UNet, $\epsilon_\theta$, and exclusively train a structure guidance module $\mathbf{s}_\theta$, leveraging a parameter copy from the UNet encoder. During inference, (c), for a video of length $N^\prime$, we construct a series of segments, each comprising $N$ successive frames. Throughout each denoising step, results for every segment are computed and aggregated. |
||
|
Video Inpainting Results
Hover over the videos to see the original video and text prompts.
Uncropping
Object Swap
Re-texturing
Content Removal
Environment Swap
Any-Length Text-to-Video Generation
A Potential Extension
| "A teddy bear walks on the beach." (80 frames) |
"A teddy bear dancing in Times Square" (256 frames) |
BibTeX
@article{zhang2023avid,
title={AVID: Any-Length Video Inpainting with Diffusion Model},
author={Zhang, Zhixing and Wu, Bichen and Wang, Xiaoyan and Luo, Yaqiao and Zhang, Luxin and Zhao, Yinan and Vajda, Peter and Metaxas, Dimitris and Yu, Licheng},
journal={arXiv preprint arXiv:2312.03816},
year={2023}
}